 |
These days we are getting better at running our project in a more agile way. We are able to produce some value at the end of each sprint. The next big step is to get this increment in the hands our customers. This is where the principles of continuous delivery come in. Continuous delivery is a set of practices and principles aimed at building, testing and releasing software. We want to do this fast and frequently. The practices and principles will help us to reduce the cost, time and risk of getting our software at the one place we really benefit from it, in production. |
I’ve seen a project where we would come together with the project manager, a couple of system administrators, a database administrator and developers a couple of days prior to our deadline. We gathered in a big room where we all worked on getting our software stable, integrated and ready for multiple production environments. This took a couple of long days. The application had many defects and we had to make a lot of last minute changes to our production code without really testing them. By that time, I hadn’t seen anything different in my career so far, I didn’t know any better. Releasing software twice a year was completely normal. One important metric in Continuous Delivery is called cycle time. It’s the time from deciding that you need to make a change to having it in production. Now I know we had a very long cycle time, way too long. Our release process was far from repeatable or reliable. Even worse, it was all manual.
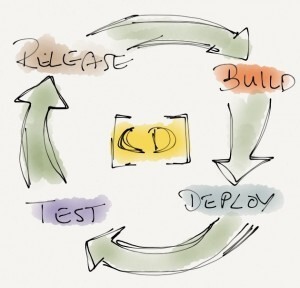
Deployment pipeline
One of the patterns that is central to continuous delivery is the deployment pipeline. A deployment pipeline is an automated implementation of your applications build, deploy, test and release process. Dependent on how an organization works, there deployment pipeline will be different. Here’s a common, simple one:

Every change we make to our application, e.g. to source code or configuration, creates a new instance of the deployment pipeline. The first stage is to build our software and for example create a setup, the rest of the pipeline is there to prove we can’t release our software. Yes, can’t. I think there is no way we could ever guarantee 100% bug free software. The thing we can do is prove that it has bugs and thereby prove we can’t release our software. Once every step in the deployment pipeline did succeed we should have enough confidence in our software to release it. To achieve the goal of delivering high-quality software in a fast, reliable and efficient manner we have to release frequently and fully automated. If we release more frequently we automatically release smaller bits. By this we are reducing the risk of our release and making it much easier to roll back in case something went wrong. Frequent releases also leads to faster feedback on what we’ve build. In the end we can only make educated guesses about what the customer wants. Until the software is in the hands of the customer they remain hypotheses. If our process of build, deploy, test and release is not automated it is not repeatable. Every time we do it, it will be different and error-prone. We cannot review exactly what was done. There’s no control over the process and we cannot guarantee quality.
How do we do it
To get to our goal we can work with the following three milestones; Deployment, Automated Deployment and Continuous delivery. Deployment is all about figuring out how we can deploy at all. What are the different pieces and components of you application? There probably is a database. How about migrations? What about a policy for dropping and creating columns etc. How many versions of our client are we going to support at once? If you’re hosting an API you will need to think about versioning that API. How to make your client communicate with the right version of you API? Now that you have defined these steps you’ll have to figure out how can these things be done without doing it manually. This is the phase in which you write scripts for these steps. It can be done with a bash or powershell script or whatever your technology stack is. This is going to surface things about your deployment strategy. You will start to figure out how to correctly version your application. You will start to figure out how different components of your application are dependent on one another and how that effects deployment. When you have created these scripts you’ll probably want to move them to some sort of automation tool. This could be for example Teamcity or TFS Buildserver. At my current project we are using Octopus Deploy.
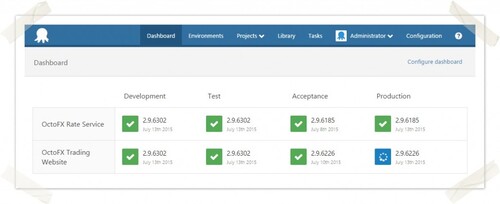
True continuous delivery, as a last phase, is about thinking and defining triggers at which the steps you have defined will be automatically run without you even touching a single button. It could be done on every check-in or by a scheduled nightly trigger. Defining these triggers is easy. The biggest problem in this phase will probably be the business. Speeding up your deployments means that your’re marketing or customer service department will have to keep up with this pace as well. There are several options to overcome these issues. One of them for example is the usage of featureflags. In another post I will discuss it more in depth. Adopting and implementing Continuous Delivery isn't an easy task. It involves a lot of small steps. It requires investment in new tooling and a re-examination of the organizational culture from all technical and business teams. I've noticed that it is easiest to start with continuous delivery right at the start of a new project. That way you'll benefit from the advantages immediately. Off course you'll benefit greatly with an existing project as well but you'll probably have to do some re-thinking on quite some decisions you've made in the past.
.png?width=450&height=450&mode=crop)